
Benchmarking Differentiable Swift
PassiveLogic’s truly autonomous control of buildings and more is enabled by the use of physics-based digital twin simulations. To match these simulations to the real world and use them to make optimal control decisions, we need to be able to run these simulations faster than real-time. Additionally, we need to be able to optimize them at the edge, not on massive servers. Differentiable programming and gradient descent optimization are the key items needed to make this possible.
As described in our recent Launch Event video, we believe that the experimental language feature of differentiable Swift is uniquely capable of performing these simulations and identifying optimal control paths. What led us to that conclusion?
The speed of differentiable Swift
Swift is a memory-safe and strongly-typed systems language. These properties make it ideal for building robust and reliable control systems. However, what really sold us on Swift for our simulations was its performance.
Early in the life of the company, we created several benchmarks of representative building simulations and the equipment operating within them. In one such benchmark, gradient descent optimization of a building model in differentiable Swift was 10,000,000 times faster than an industry-standard building optimizer without gradient descent.
I want to highlight another benchmark, one that we just published to our open source differentiable Swift examples repository. This is the benchmark behind our recent public speed claims, which show a building simulation created in differentiable Swift operating 238X faster than PyTorch and 322X faster than TensorFlow. But…what is being measured here, and why is that important to us?
Watch our benchmark speed test in the PassiveLogic 2023 Launch Event.
We can describe heat transfer in terms of relatively simple equations. However, we may not know some of the equations’ parameters, and therefore need to optimize those parameters to match the known behavior of the system. That known behavior could be temperature measurements from sensors as a function of time, the recorded external weather, or any other data we have about the building or equipment.
The system we’re modeling in this benchmark is a simple one involving a tank, a flat radiator slab, and a pipe connecting them. Heat flows between the tank and the slab. We may not know some of the parameters of this system, but we know the ending temperature of the slab. We can then use gradient descent optimization to best fit the system to the known data.
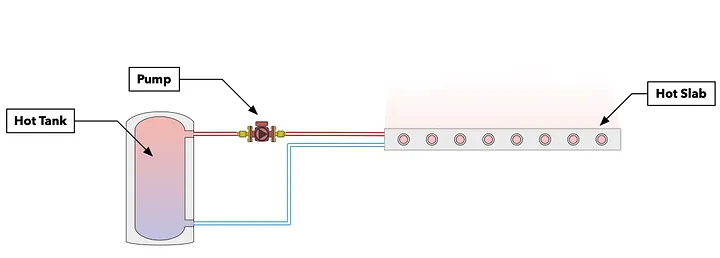
A schematic of the equipment system we are modeling for this benchmark.
Because we needed gradient descent to perform our optimizations, we wanted to test various common technologies that had this capability. The most popular are the neural network training frameworks, like PyTorch and TensorFlow, which build in automatic differentiation as a library capability. These frameworks typically use Python as an interface language and C++ under the hood for performance.
We implemented the same calculation in differentiable Swift, PyTorch, and TensorFlow, and verified the numerical results for forward and backward passes to ensure they matched. I performed these benchmarks on an M1 Pro MacBook Pro, with all frameworks running purely on the host CPU. The following are the average timings for the combined forward + backward passes through the model, along with the relative slowdown of the other frameworks compared to differentiable Swift:
+------------+------------+-----------+ | Version | Time (ms) | Slowdown | +------------+------------+-----------+ | Swift | 0.03 | 1X | | PyTorch | 8.16 | 238X | | TensorFlow | 11.0 | 322X | +------------+------------+-----------+
Why is differentiable Swift so much faster in this benchmark? PyTorch and TensorFlow both excel at massively parallel calculations, especially when you can dispatch them on GPUs or other accelerators. However, in this case, we have only scalar calculations for the components of this heat transfer model, with the structure defined using types that express the component being simulated. Frameworks like PyTorch and TensorFlow rely on batching up parallel computation and dispatching that to accelerators or the CPU, and there’s overhead in that dispatch mechanism. In the Swift case, these calculations are compiled and run directly, without any dispatch overhead.
Like many current neural network frameworks, PyTorch and TensorFlow use Python as a host language. Python has performance disadvantages when compared to an ahead-of-time compiled systems language like Swift. The more time that a model spends in the high-level Python logic versus in the optimized C++ code under the hood, the greater this performance disadvantage becomes.
It’s for these reasons that this problem, which is very important for us to simulate, is well outside of the sweet spot for traditional neural network frameworks.
This is one representative case for where differentiable Swift can be significantly faster than alternatives, but is only one of many inside of our simulation and control systems. We believe there is a world of applications out there that have not won the software lottery and are not well-served by current frameworks. We hope that differentiable Swift can enable those new applications.
I invite you to try out these benchmarks for yourself. Our examples repository has the full code for them, along with instructions for how to set up and run Swift, PyTorch, and TensorFlow environments for each benchmark variant. In addition, the main repository contains examples of how to use differentiable Swift along with documentation and detailed tutorials.
Additional Swift benefits
A fascinating aspect of Swift is that this speed doesn’t come at the expense of readability. Python is a language known for being easy to read, but it’s not common to say the same about a systems programming language. Compare the same function in our benchmarks written in Python (for PyTorch):
def updateQuanta(quanta):
workingVolume = (quanta[QuantaIndices.iflow] * dTime)
workingMass = (workingVolume * quanta[QuantaIndices.idensity])
workingEnergy = quanta[QuantaIndices.ipower] * dTime
TempRise = workingEnergy / quanta[QuantaIndices.iCp] / workingMass
resultQuanta = quanta + TempRise * torch.tensor([0.0, 1, 0, 0, 0])
resultQuanta = resultQuanta * torch.tensor([0.0, 1, 1, 1, 1])
return resultQuanta
with the same in Swift:
@differentiable(reverse)
func updateQuanta(quanta: QuantaType) -> QuantaType {
let workingVolume = (quanta.flow * dTime)
let workingMass = (workingVolume * quanta.density)
let workingEnergy = quanta.power * dTime
let TempRise = workingEnergy / quanta.Cp / workingMass
var updatedQuanta = quanta
updatedQuanta.temp = quanta.temp + TempRise
updatedQuanta.power = 0
return updatedQuanta
}
Developers can express the same concepts in a very readable manner in Swift code while maintaining strong type checking and value semantics. As an additional benefit, because we can differentiate the Swift code directly, there’s no need to cram variables into a tensor-like type to take advantage of automatic differentiation (like for the popular Python frameworks we’ve used here).
There are, of course, other capabilities that come with incorporating differentiability into a fast systems language. We can write our entire control platform, our simulations, and our control path-finding in the same language. It’s hard to say where one area of functionality begins and the other ends, unlike traditional machine learning deployments with hard boundaries between systems code and ML code.
Ongoing optimizations
It is a goal of ours to make differentiable Swift even faster. For example, two years ago we wrote an article where we compared the speed of differentiable Swift against derivatives generated using the Enzyme framework. At that time, the Enzyme-generated derivative code was 477X faster than equivalent differentiable Swift. About a year later, we landed a significant optimization for simple differentiable Swift functions that eliminated this performance gap, and now the Enzyme and Swift examples in that article are roughly equivalent in speed.
We’ve made significant improvements in the speed of differentiable Swift over just the last year. The same Swift building simulator we use here shows a 2.4X improvement in performance when built using nightly Swift toolchain snapshots starting in January and running through September. We are currently prototyping an optimization that, in initial tests, leads to a further 5.4X improvement over today’s nightly Swift toolchains. This totals a roughly 13X speedup since the start of 2023.
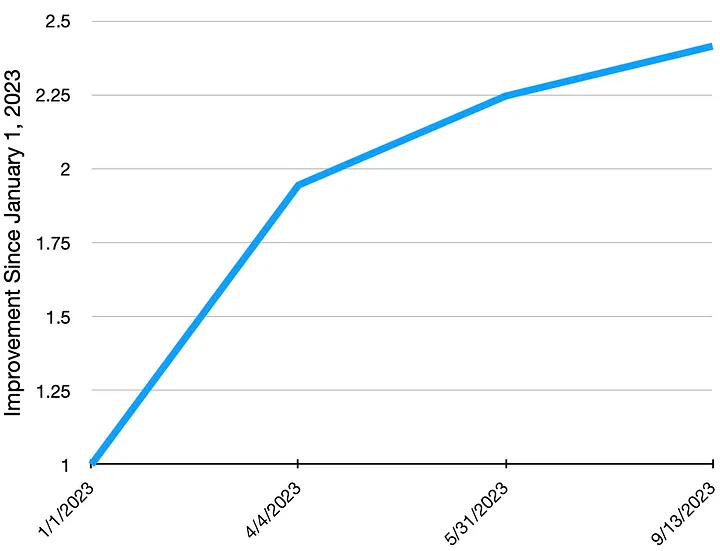
The improvement in performance of our differentiable Swift simulator benchmark in nightly Swift toolchain snapshots over 2023.
In the published roadmap for differentiable Swift in 2023, we described how less and less of our development effort would be needed to fix correctness issues and more time would then be devoted to optimizing the code generated by this language feature. We’re only starting to see the results of this, and I’m excited for what the next several months will bring.
